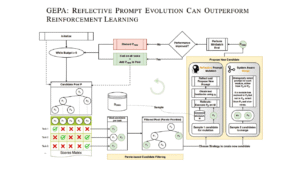
GEPA: um novo paradigma para otimização de prompts que supera o Reinforcement Learning 24/03/2026 Acessar Conteúdo »
Geometric-Mean Policy Optimization (GMPO): Um Novo Passo para Otimizar a Estabilidade e o Raciocínio em LLMs 24/03/2026 Acessar Conteúdo »
Underthinking em Modelos de Linguagem: Um Desafio para o Raciocínio Profundo da IA 24/03/2026 Acessar Conteúdo »